On November 28, the Irish data protection authority, the Data Protection Commission (DPC), fined Facebook parent company Meta $277 million for two violations of the General Data Protection Regulation (GDPR).
Attackers were able to obtain the data of more than 533 million users over an extended period of time by exploiting a security weakness.
This is the fourth fine imposed on Meta by the authority. In total, the DPC has now imposed a fine of just under $1 billion on the company.
What happened?
In April 2021, a hacking forum published a dataset of more than 533 million Facebook users that included a lot of personal data.
The disclosed data included the personal information of Facebook users from 106 countries, including 32 million from the United States and 11 million from the United Kingdom. The dataset contained mobile phone number, Facebook ID, name, birthday, and in some cases email address, among other information.
Malicious attackers were able to automatically harvest the user data over an extended period in 2018 and 2019 via a vulnerability in the contact import tool. Facebook stated that it had fixed the vulnerability and would like to explicitly emphasize that it was not a hack of the platform, but rather so-called “scraping” of publicly accessible APIs.
With the GDPR coming into force in May 2018, the Irish Data Protection Authority investigated various tools of Facebook, including Facebook search and contact import in Facebook and Instagram. The outcome of the investigation identified deficiencies in technology design (Privacy by design – Article 25 (1) GDPR) and with regard to privacy-friendly default settings (Privacy by default – Article 25 (2) GDPR). According to the DPC, Facebook failed to design its products to prevent scraping attacks.
In addition to the fine, the DPC has also imposed a three-month period on parent company Meta, within which the group must take a number of measures to bring the processing of personal data into compliance with the regulations of the GDPR.
What is scraping?
Web scraping is a term for various methods used to automatically collect information from the Internet. As a rule, this is done with the help of bots that simulate human behavior on websites and automatically extract content.
In addition to the legitimate use of so-called scraper bots, e.g. by search engines or as part of market research, there are also malicious bot developers who use the software to collect personal data by exploiting security vulnerabilities on websites or APIs.
Scraping is the new hacking
Bots are responsible for more than half (57%) of all web traffic today. Facebook is not alone in facing the problem of web scraping. Shortly after the Facebook data leak became public in April 2021, reports surfaced that the social network Clubhouse had also exposed vast amounts of user information through its API.
LinkedIn was also hit by a “scraping attack” a short time later, in which data from over 500 million users was accessed via publicly available APIs.
In most cases, the automatic reading of this information violates the terms and conditions of the social networks, and Facebook has already sued several companies over this in the past.
Nevertheless, a clear picture is emerging: with so many public APIs and data, it is no longer necessary for malicious attackers to “hack” the systems in the classic sense these days. All they have to do is collect already accessible data in an automated manner and, if necessary, merge it to capture complete data sets from millions of users.
Protect your company from scraper bots
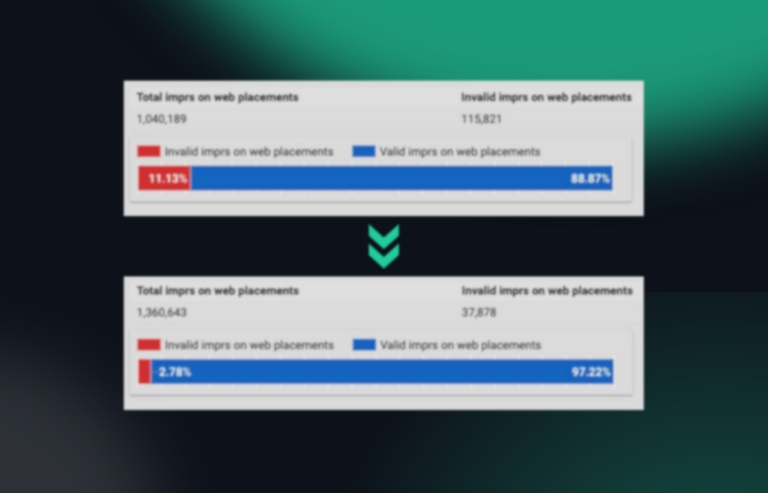
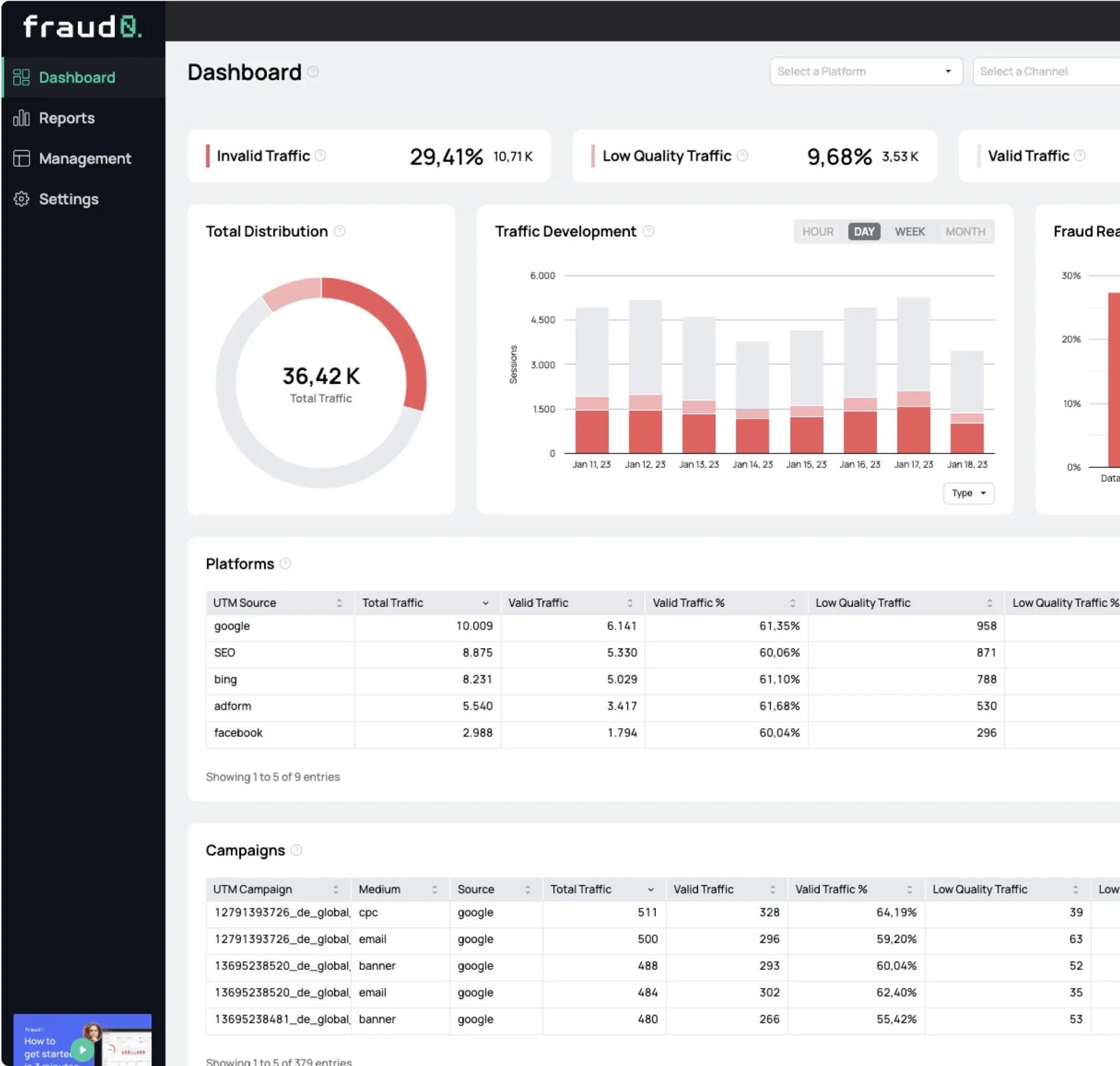
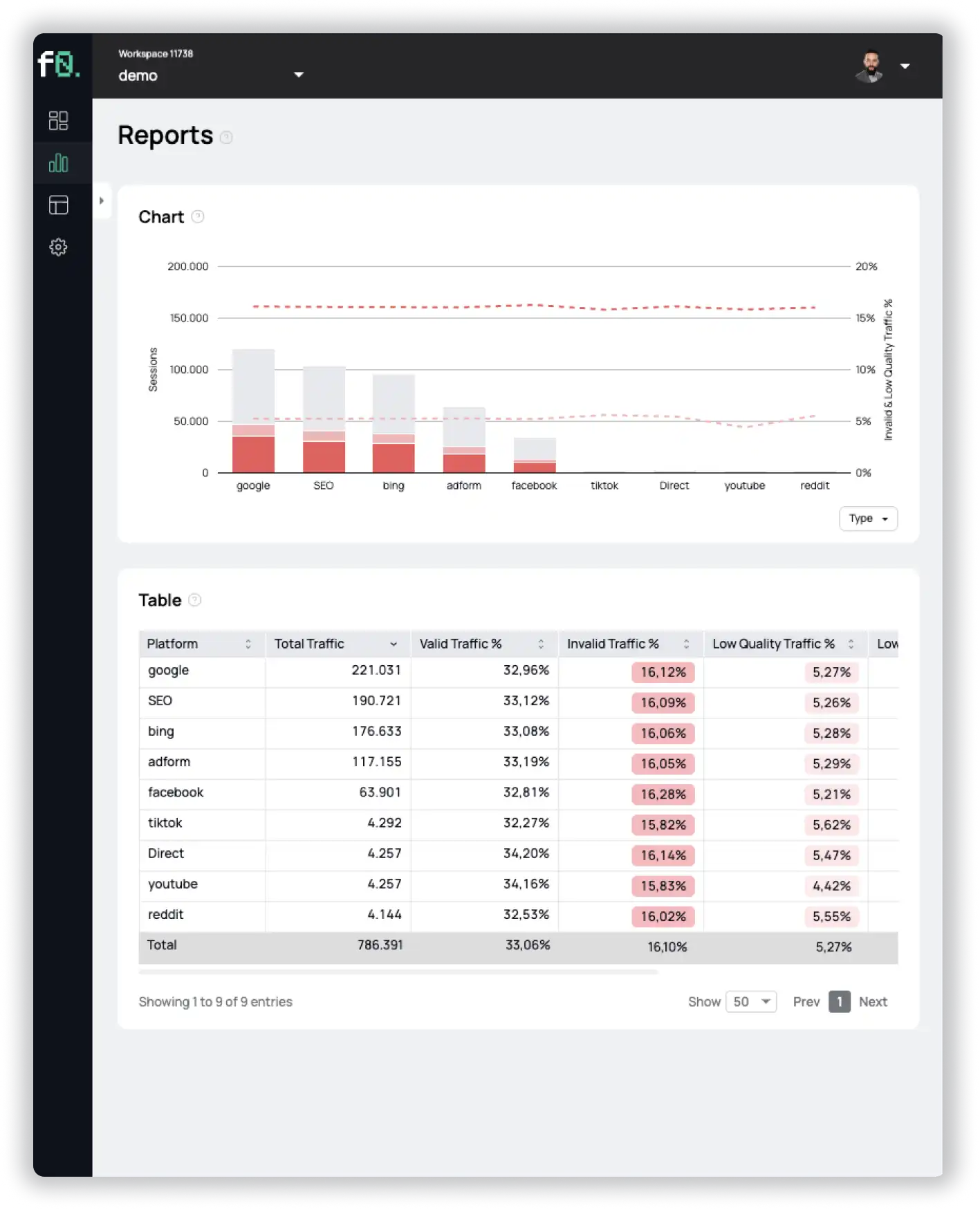
In order to reliably protect your business from scraping attacks, you need to have software in place to detect bots. fraud0 can help you here. Our software detects and blocks bots in real time, preventing them from accessing your website.
Sign up for a free 7-day trial today and see for yourself!
-
Published: December 5, 2022
-
Updated: July 2, 2025